最近项目里遇到了一些解析层面上的问题,主要是输入的文本如何高效解析出好的内容,刚开始用的是 markitdown,最近微软新开源的一个项目,但是遇到了一个很明显的问题就是把内容切的很碎,导致几乎无法使用了,后来又找了几个 MinerU,但是效果还是不行,后来又继续找,找到了这个项目,感觉效果还不错,所以分享一下。
Marker 是一个功能强大的开源工具,旨在将PDF和图像文件快速且准确地转换为Markdown、JSON和HTML格式。本文将从功能特性、商业使用、托管API、社区支持、安装与使用以及目录结构等方面详细介绍该工具。
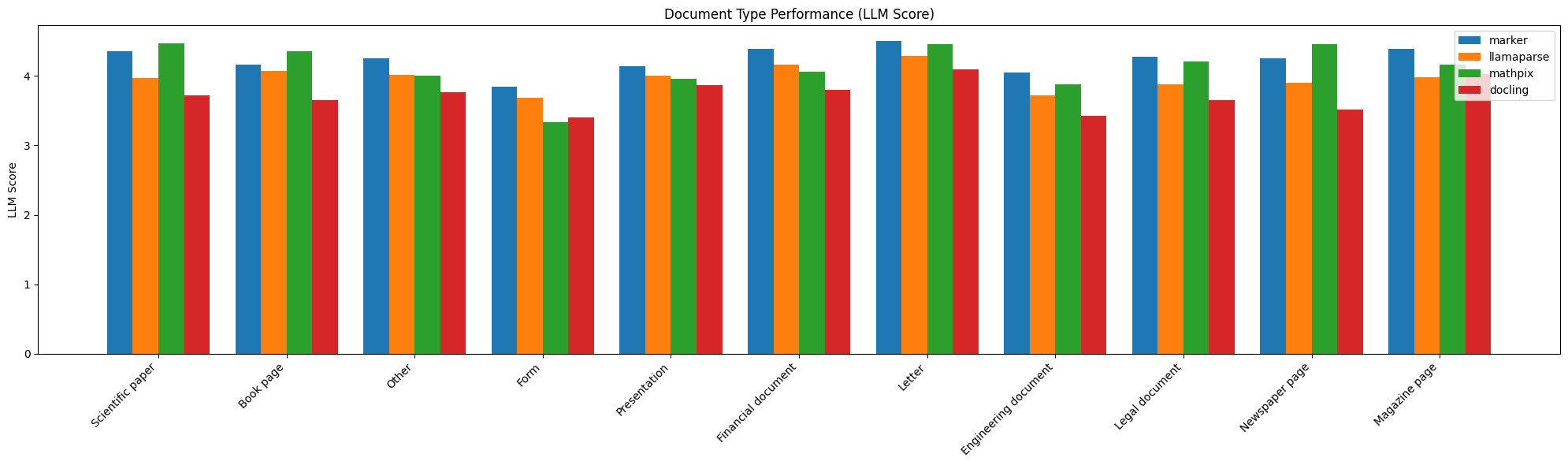
| Document Type | Marker heuristic | Marker LLM | Llamaparse Heuristic | Llamaparse LLM | Mathpix Heuristic | Mathpix LLM | Docling Heuristic | Docling LLM |
|---|---|---|---|---|---|---|---|---|
| Scientific paper | 96.6737 | 4.34899 | 87.1651 | 3.96421 | 91.2267 | 4.46861 | 92.135 | 3.72422 |
| Book page | 97.1846 | 4.16168 | 90.9532 | 4.07186 | 93.8886 | 4.35329 | 90.0556 | 3.64671 |
| Other | 95.1632 | 4.25076 | 81.1385 | 4.01835 | 79.6231 | 4.00306 | 83.8223 | 3.76147 |
| Form | 88.0147 | 3.84663 | 66.3081 | 3.68712 | 64.7512 | 3.33129 | 68.3857 | 3.40491 |
| Presentation | 95.1562 | 4.13669 | 81.2261 | 4 | 83.6737 | 3.95683 | 84.8405 | 3.86331 |
| Financial document | 95.3697 | 4.39106 | 82.5812 | 4.16111 | 81.3115 | 4.05556 | 86.3882 | 3.8 |
| Letter | 98.4021 | 4.5 | 93.4477 | 4.28125 | 96.0383 | 4.45312 | 92.0952 | 4.09375 |
| Engineering document | 93.9244 | 4.04412 | 77.4854 | 3.72059 | 80.3319 | 3.88235 | 79.6807 | 3.42647 |
| Legal document | 96.689 | 4.27759 | 86.9769 | 3.87584 | 91.601 | 4.20805 | 87.8383 | 3.65552 |
| Newspaper page | 98.8733 | 4.25806 | 84.7492 | 3.90323 | 96.9963 | 4.45161 | 92.6496 | 3.51613 |
| Magazine page | 98.2145 | 4.38776 | 87.2902 | 3.97959 | 93.5934 | 4.16327 | 93.0892 | 4.02041 |
功能特性
1. 文档支持
Marker 支持多种语言的文档处理,并能够格式化以下内容:
- 表格、表单、方程式、行内数学公式
- 链接、引用和代码块
- 提取并保存图像
- 移除页眉、页脚等干扰元素
- 支持用户自定义格式化和逻辑扩展
2. 性能表现
Marker 在性能上表现出色,尤其是在批量处理时:
- 单页PDF串行处理效果良好
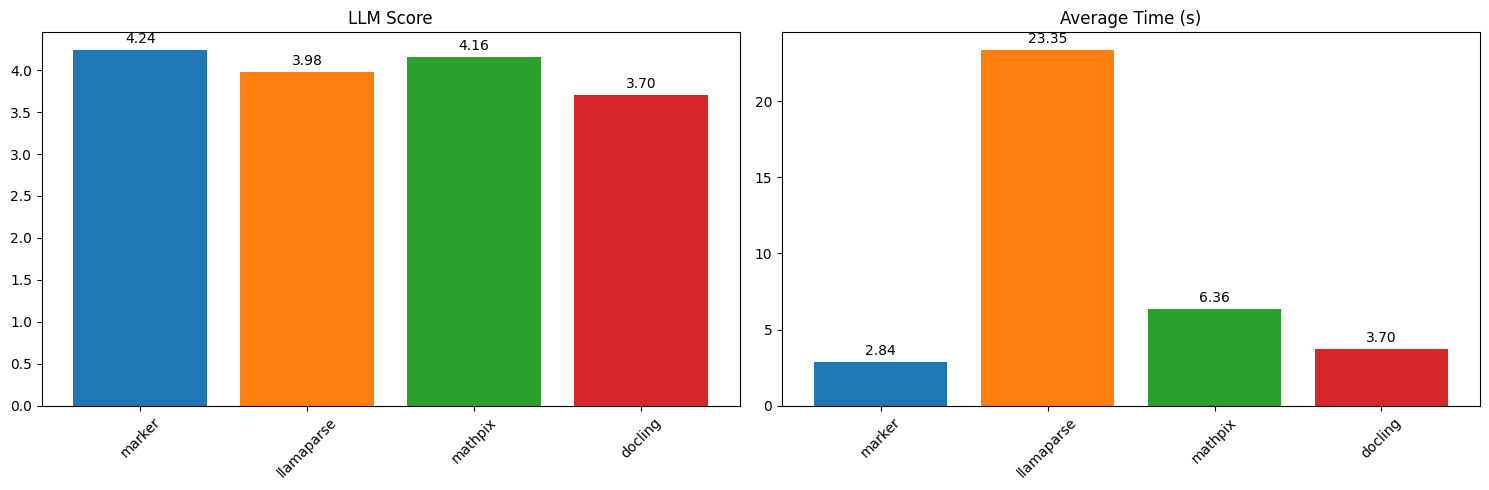
- 批量处理速度显著提升,在H100上预计吞吐量为122页/秒(22个进程下每页约0.18秒)
- 与云服务(如Llamaparse和Mathpix)及其他开源工具相比,性能更优
3. 混合模式
通过传递 --use_llm 标志,可以使用大语言模型(LLM)来提高准确性:
- 合并跨页表格
- 处理行内数学公式
- 正确格式化表格
- 从表单中提取值
- 默认使用
gemini-2.0-flash模型,也支持其他gemini或ollama模型
4. 示例展示
Marker 提供了一些示例文档的转换结果,包括:
- 《Think Python》
- 《Switch Transformers》
- 《Multi-column CNN》
你可以去代码仓库查看下 Markdown和JSON格式的转换效果,个人觉得还是不错的。
商业使用是不受限的
但是需要遵守开源协议,不能与 Datalab API 竞争
托管API
Marker 提供托管API服务,地址为 https://www.datalab.to/,主要特点包括:
- 支持格式:PDF、Word文档和PowerPoint
- 价格优势:仅为领先云竞争对手的四分之一
- 高性能:高可用性(99.99%)、高质量和高速度(约15秒可转换250页的PDF)
安装与使用
1. 安装
- 环境要求:Python 3.10+ 和 PyTorch
- 如果不使用Mac或GPU机器,可能需要先安装CPU版本的torch
- 安装命令:
pip install marker-pdf
2. 使用
- 配置设备:例如
TORCH_DEVICE=cuda - OCR处理:
- 对于文本质量不佳的PDF,可以设置
force_ocr标志强制进行OCR处理 - 或设置
strip_existing_ocr标志保留数字文本并去除现有OCR文本
- 对于文本质量不佳的PDF,可以设置
- 交互式应用:
- 安装
streamlit:pip install streamlit - 运行
marker_gui启动交互式应用程序
- 安装
- 单文件转换:
- 使用
marker_single /path/to/file.pdf转换单个文件 - 支持多种选项,如指定输出目录、输出格式、分页输出、使用LLM、禁用图像提取、指定页面范围和强制OCR等
- 使用
主要文件夹说明
tests/:测试文件夹,包含单元测试和集成测试builders/、converters/、processors/、providers/、renderers/、schema/、services/:功能模块文件夹,分别处理不同的转换逻辑benchmarks/:基准测试文件夹,用于性能评估static/:静态资源文件夹,存放CSS、JS等文件.github/:GitHub相关配置文件夹,包含CI/CD配置data/:数据文件夹,存放示例数据或测试数据
总结
Marker 是一个功能强大且高效的文档转换工具,适用于研究、个人使用以及符合条件的商业场景。通过其丰富的功能特性、高性能表现和灵活的扩展能力,Marker 能够满足用户对PDF和图像转换的多样化需求。无论是通过本地安装还是托管API,Marker 都提供了便捷的解决方案。
我综合了多个效果对比,包括 markitdown、MinerU、marker,最后选取了 marker,效果还不错,推荐使用,大家有什么更好的工具也可以推荐一下,欢迎留言。